y = x + k*x*(1-x) (Equation 2.1)
We can easily solve the above equation algebraically to find y given the values for k and x. Normally, we assume a constant value for k and solve for different input values of x. For example, if k=2 and x=.5, then
y = .5 + 2 * .5 * .5 = 1
Let's conduct a mathematical experiment using this function. Instead of choosing our x-values from a range of, say, 0 to 5, let's use the function itself to choose the next value of x. In other words, given a starting 'seed' value for x (while holding k constant) we solve the equation for y, then use this result as the new value for x. We solve the equation again, and repeat the process many times. This process of 'mathematical feedback', that is, feeding the output (y) back around to the input (x), is called iteration.
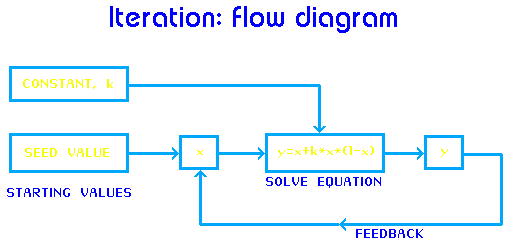
What happens to y when we iterate the function as described above? To find out we will try an experiment, performing the iteration with a pocket calculator.
In the above experiment, you may have concluded that iteration is indeed a tedious process, even with the aid of a calculator. As mentioned earlier, the computer is very well suited to such tasks and with it we can make discoveries in moments that could take days or weeks using other methods. There is a program called IT that can be used to iterate our function for us and display or print the results.
IT asks for three parameters: a k-value, seed value, and iteration count. If you have a printer attached to your computer you may direct the results of the last 'n' iterations to the printer. Since it is usually the later iterations that are more significant you may wish to print only the last twenty or so, especially if the iteration count exceeds 100 or more. A sample printer output is shown in Fig. 2-3 below.
You can repeat the calculator experiments using IT. It will now take only moments to compare the results when different k or seed values are used, and you may perform the iteration thousands of times if you wish.
Fig. 2-3 A sample run of the program IT:
IT! V 1.0 D.Martin (c) 1994 EALSoft Iterations of the function: y = x + k * x * (1 - x) Seed= 0.3500000000 k= 1.9100000000 Iteration 41 0.9976991645 Iteration 42 1.0020836491 Iteration 43 0.9980955869 Iteration 44 1.0017260888 Iteration 45 0.9984235686 Iteration 46 1.0014298060 Iteration 47 0.9986949719 Iteration 48 1.0011843227 Iteration 49 0.9989195874 Iteration 50 1.0009809460
Seed value k-value Iteration
Count
.2 1.5 100
.4 1.5 100
.3 2.25 100
.6 2.25 100
.2 2.52 100
.4 2.52 100
.2 2.755 100
.3 2.755 1000
You may have noticed that for some values of k the iterations eventually result in a single, repeating value. For other values of k the result alternates between two values. For yet others, three, four or more values. There are some k-values for which no discernible pattern of values emerges no matter how many iterations are performed.
Look again at the results using the first two sets of parameters above. Notice that in each case the result of iteration, regardless of the seed value, approaches the value 1.0000. This number is called the 'attractor' for the function when k=1.5, because the solution seems to be 'attracted' to this number. The function may or may not have a different attractor for different values of k. For some values, such as k=2.25, the attractor is a set of two numbers. Experiment with other values for k and try to find the attractor for the function. Fig. 2-4 shows the attractor for the parameters used in Fig. 2-3.
Fig. 2-4 Attractor value for Seed = 0.35, k = 1.91
IT! V 1.0 D.Martin (c) 1994 EALSoft Iterations of the function: y = x + k * x * (1 - x) Seed= 0.3500000000 k= 1.9100000000 Iteration 216 1.0000000002 Iteration 217 0.9999999999 Iteration 218 1.0000000001 Iteration 219 0.9999999999 Iteration 220 1.0000000001 Iteration 221 0.9999999999 Iteration 222 1.0000000001 Iteration 223 0.9999999999 Iteration 224 1.0000000001 Iteration 225 0.9999999999 Iteration 226 1.0000000001 Iteration 227 0.9999999999 Iteration 228 1.0000000000 Iteration 229 1.0000000000 Iteration 230 1.0000000000 <---Attractor
So far our results do not reveal anything terribly interesting, but these experiments were necessary to gain an understanding of the next exercise.
We have seen that the equation
y = x + k*x*(1-x) (Equation 2.1)
produces an inverted parabola when we plot x versus y. We have also seen that when iteration is performed using different values for k, different attractors are found. Let's use the same data, but represent it in a different way. Rather than plotting the equation in the normal way (ie. inverted parabola), or listing the numerical values for the attractor, let's plot the attractor for the function over a range of k-values. You may try this with the IT program and a piece of graph paper if you wish, but you will again find the computer to be an essential tool. A supplemental program, called BIF, does the tedious work, leaving us with more time to study the results.
BIF was created specifically for generating bifurcation diagrams (hence the name, BIF) derived from the function
y = x + k*x*(1-x) (Equation 2.1)
We will discuss the significance of this term later in this exercise. You may run the program by entering 'BIF' at the DOS prompt. After the opening screen, you will see a display of BIF's default parameters and a command menu. See the BIF User Guide for details about program operation and program parameters.
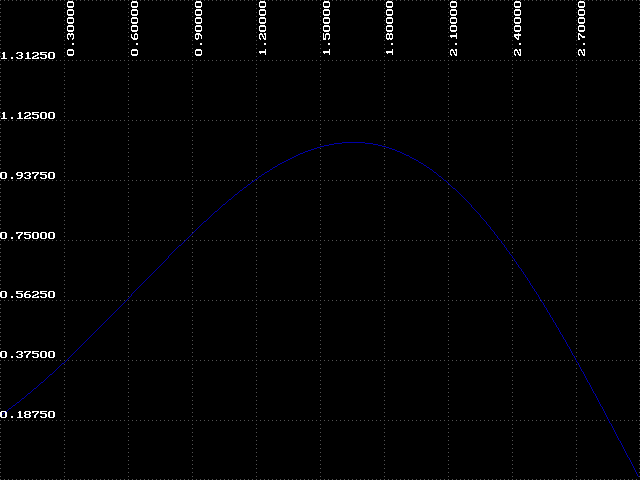
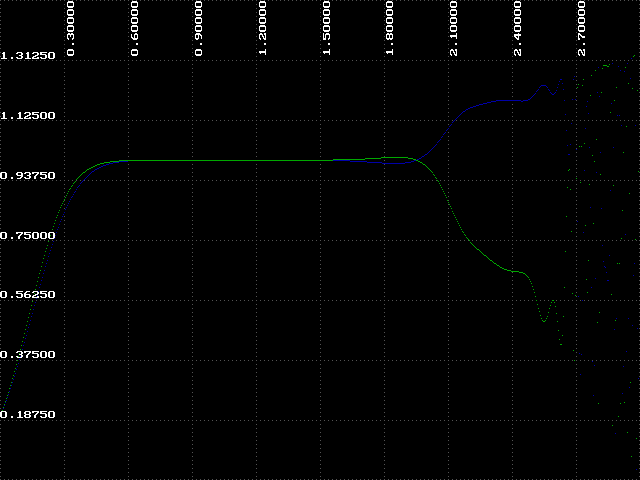
This is where we will continue our experiments. It is important to remember that the values for k will be plotted on the x-axis of the graph, while y-values remain on the y- axis.
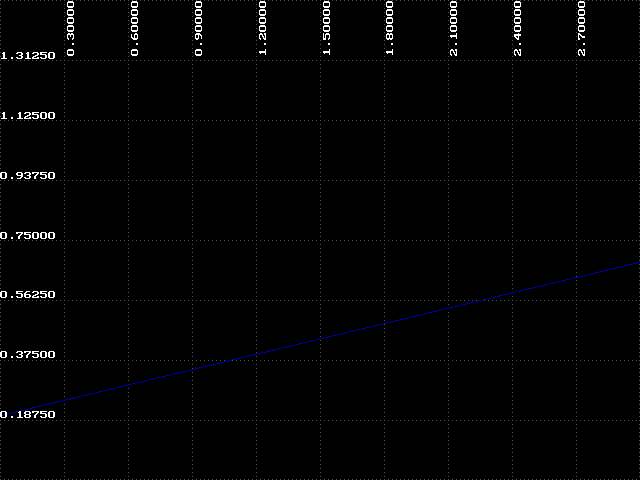
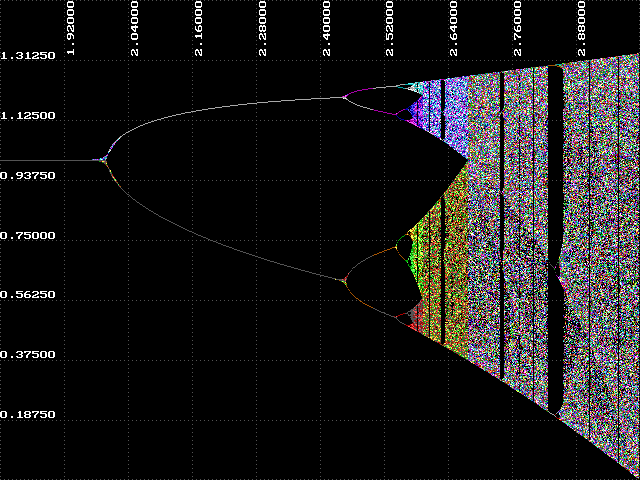
If you are able to output the graphs to a printer, it would be helpful to compare them side by side. Lets first consider one particular region of the graphs - the region from k=0 to k=1.5, or the left half. Can you spot a trend in this region as the iteration count increases? Look back at the results you obtained using IT with k=1.5. Remember that the attractor for k=1.5 was 1.00000? What do these graphs indicate?
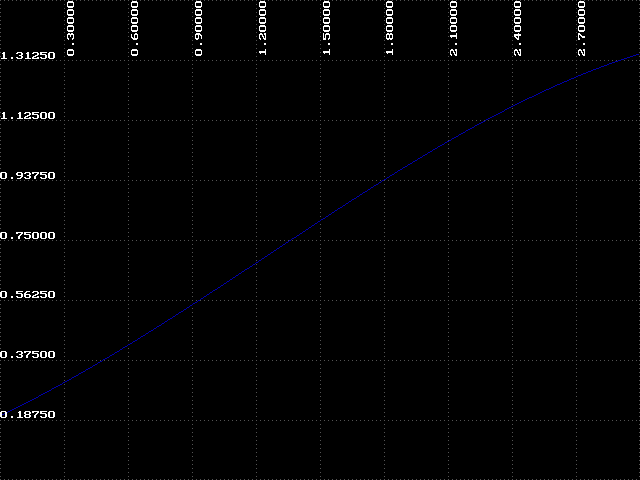
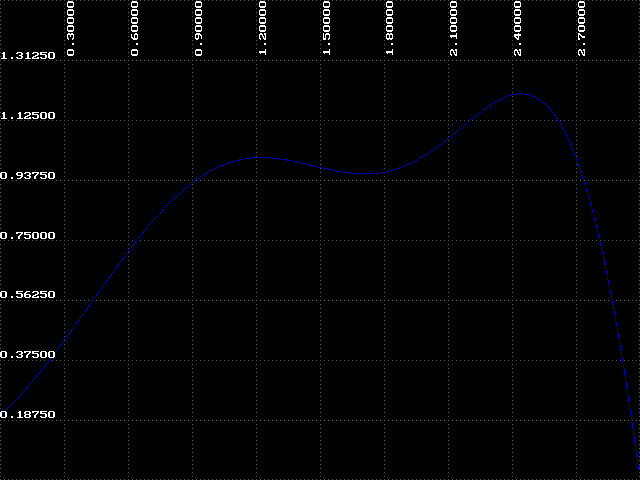
What about the region to the right of k=1.5? Look again at the data you collected using IT, this time where k=2.25. Remember that the attractor alternated between two values at this point? Our graphs show only a single line. Why? The next experiment will help answer this question.
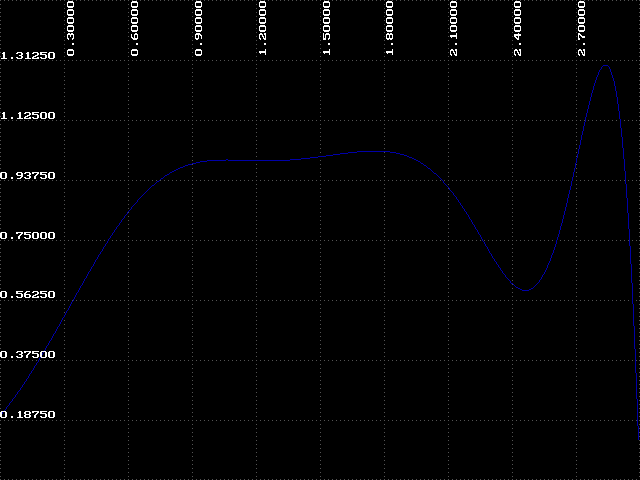
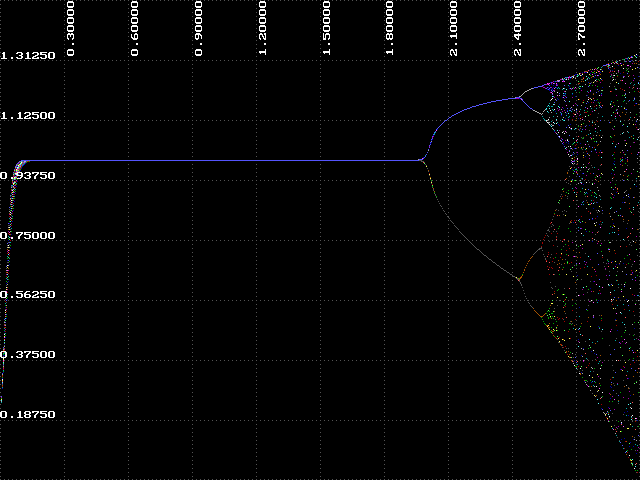
After seeing the results of step 5 in Experiment 2.4, we can conclude a number of things. One conclusion is that the region where k < 1.8 is very orderly and predictable and, consequently, somewhat boring. However, the region where k > 1.8 is far more interesting. To get a closer look at this region we can zoom in by expanding a portion of the graph. We can do this easily by changing the Left parameter to 1.8. Try it and repeat step 5 from Experiment 2.4.
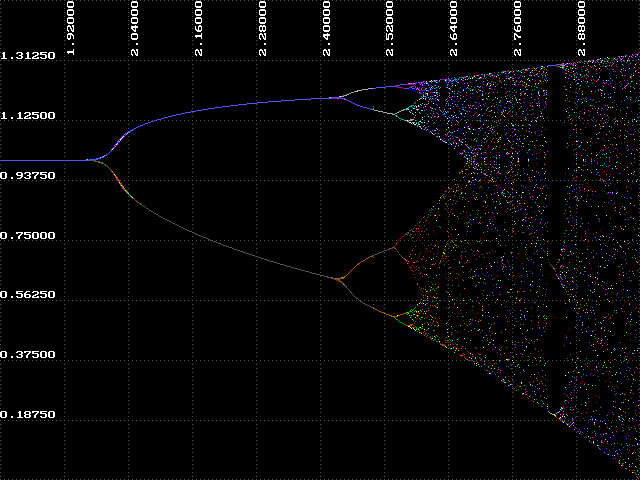
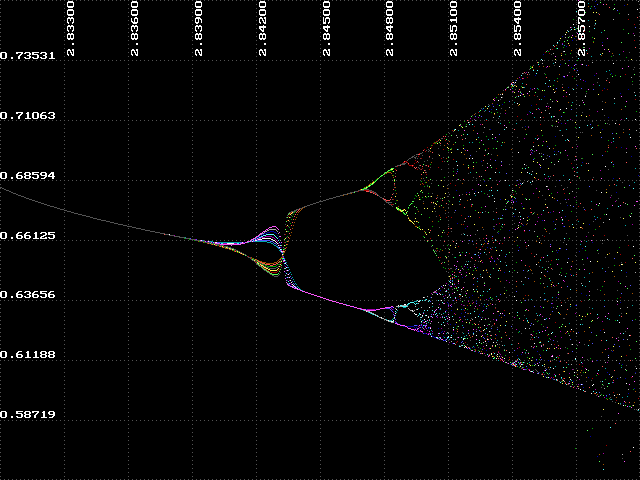
Now we can discuss how BIF got its name. The graphs we have been looking at are called bifurcation diagrams. Bifurcation means 'branching' or 'splitting', and we can see that the attractor branches at various points between k=1.9 and k=2.56. This region is called the 'bifurcation region', and the branching is sometimes called 'period-doubling' because at each of these branch points the number of values in the attractor doubles.
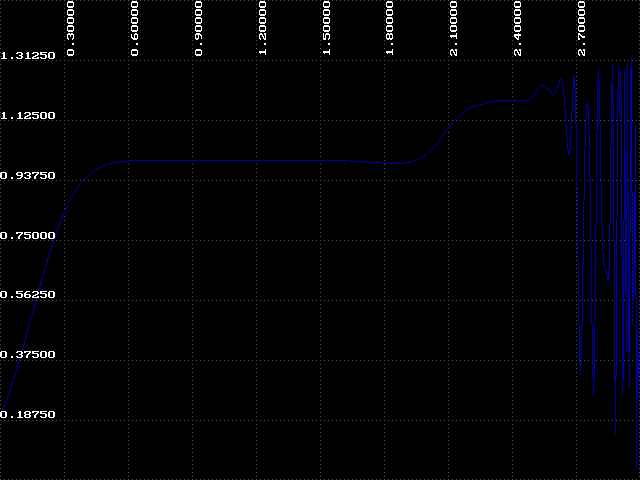
So far we have identified two regions of the bifurcation diagram. The first we will call 'order', where k < 1.8. In this region we know that the attractor will always approach a constant value, in this case, one. The second is the bifurcation region, which we have just examined. There is a third region where k > 2.6. Here we cannot make any general statement about the behavior of our function. The attractor is disordered and unpredictable - we call this region 'chaos'. There is something very interesting about this chaotic region which we will explore in the next experiment.
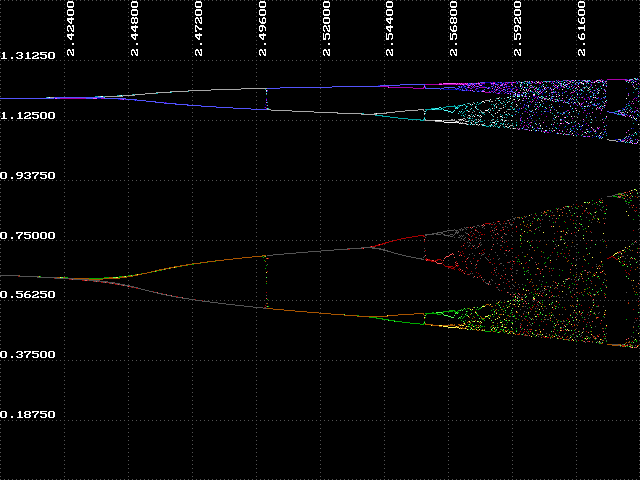
You probably have noticed that the bifurcation diagram contains smaller regions that resemble the entire diagram when we zoom in on specific areas. This is a characteristic of many fractals and is called self-similarity. When we look at the bifurcation diagram from k=1.5 to k=3 we see the progression from order to bifurcation to chaos. When we magnify a small region of chaos we can see another similar progression, but on a smaller scale. The following experiment demonstrates this characteristic.
When self-similarity occurs as a result of iteration, it appears to be 'by accident'. Without prior knowledge we could not have guessed that self-similarity would occur. It was mentioned earlier that fractal geometry is the 'geometry of nature'. Self-similarity is a natural phenomenon; it occurs not only in fractals, but is also prevalent in nature from the magnificent to the minute. Consider the branching of trees or a river and its tributaries. A small flake of rock, when magnified, is indistinguishable from a boulder, and atoms might be said to resemble solar systems.
Each k-value in the ordered and bifurcation regions has a clearly discernible attractor. In the regions of chaos there is no specific, definable attractor. However, we can see that all values for y in these regions fall within a range of values. We call this, and the whole bifurcation diagram itself, a strange attractor.
As mentioned in the beginning of this section, there are many variations of the 'population equation' which will produce results similar to our 'BIF' equation. One condition is that it must be an equation for a non-linear function having a single hump in its curve.
The creators of BIF encourage you to take some time to play. You may have already discovered some regions and sets of parameters which you find especially interesting or even beautiful. Below are some suggested parameter sets which you may wish to explore.
Left 2.56 2.56
Right 2.57 2.5644
Top 1.24 1.239
Bottom 1.2363 1.237
Invisible 12 12
Visible 500 500
When experimenting with your own values be aware that some slower computers may take a very long time to complete a graph if large iteration counts are used. The maximum allowable value for Invisible and Visible is 32767. In one test in which 1000 invisible and 1000 visible iterations were performed, a 12MHz 80286 completed it in 12.5 minutes.
If time allows, run BIF with the following parameters: Left=1.8, Right=3.0, Top=1.5, Bottom=0, Invisible=100, Visible=1000. Notice that within the chaotic regions there are very clearly defined regions of order contrasting against the chaos, no matter how many visible iterations are performed.
Return to Table of Contents
Continue to next section
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}